转载——IT168
在 AI 全面触达各行各业的今天,从初学者、开发者到极客与内容创作者,越来越多人希望将大模型部署于本地,以摆脱云端限制,实现低延迟、高私密、可掌控的 AI 应用体验,极摩客 EVO-X2桌面Mini AI工作站恰好为此提供了新方案。
极摩客 EVO-X2可覆盖多元用户需求,对 AI 相关的学生、初创团队及独立开发者而言,它能提供可靠的本地 AI 实验平台,方便开展模型适配、验证与应用开发工作;针对内容创作者,其性能可满足视频剪辑、3D 建模等专业需求,无论是作为灵活的移动工作站,还是充当家庭娱乐中心的 AI 中枢都十分合适;而对于硬核玩家,它既能支撑 3A 游戏运行,又能实现 AI 辅助功能,让玩家在沉浸游戏体验的同时,感受 AI 带来的全新玩法。

其最大亮点在于搭载的AMD锐龙 AI Max+ 395 处理器。这款处理器基于先进的 “Zen 5” 架构,拥有 16 颗超大核心 32 线程,最高频率可达 5.1GHz,80MB (L2+L3)缓存配合 40 个 RDNA 3.5 计算单元的 Radeon 8060S 集成显卡,图形性能大幅跃升。同时,它还集成了 50 TOPS “XDNA 2”架构的NPU,70B稠密模型在 LM Studio 中的 AI 性能比 台式机中的NVIDIA GeForce RTX 4090独显还高出 2.2 倍,且功耗降低了87%。它能支持本地运行200B以上参数规模的量化语言模型,以往需昂贵专业服务器或高端独显才能完成的任务,如今在这台桌面Mini AI工作站上就能高效实现。例如Qwen-3的235B模型推理速度达到14tokens/sec,以及openAI最新开源的GPT-OSS-120B推理速度达40tokens/sec。
极摩客EVO-X2的另一大亮点在于其强大的AI计算能力。得益于锐龙AI Max+ 395处理器的统一内存架构,128GB的超大统一内存可动态调节至高96G显存,这款迷你PC能够轻松应对各种AI计算任务,甚至能够本地部署和运行大规模的语言模型
外观:极简科幻,小巧精致
作为一款面向 AI 开发的桌面 Mini AI工作站,极摩客 EVO-X2在外观设计上强调 “小体积,大能量”。整机采用一体化的 “再生铝” 合金机身结构,银黑配色的极简工业风,小巧的机身尺寸约 192×186×77mm,可立可卧,非常适合摆放在工作室、实验室乃至宿舍的桌面上。全铝外壳不仅保证了坚固质感,也有助于散热稳定,高负载运行时机身仍能保持良好温控。

机身前面板除了一个圆形绿色的电源按键,还专门设计了一个P-Mode性能模式切换的按键,为用户带来更加灵活高效应对多场景应用的需求。此外,前面板还提供了 1 个 SD 卡插槽,1 个Type-C USB4,2 个USB 3.2,1 个 3.5mm 耳机/麦克风插孔。

侧面采用多边形设计风格,左上角有极摩客的Logo,旁边则是切换风扇模式的三角形按钮,这样的设计不仅增添了科技感,也提高了实用性。


机身后置的端口提供了 2 个USB 2.0,1 个 HDMI 2.1,1 个 DP1.4,1 个Type-C USB4,1 个 USB3.2(Gen2),1 个 RJ4.5 有线端口,3.5mm 耳机/麦克风插孔及电源接口。此外也提供了一个安全锁孔,对于小型机而言,还是很有必要的。

除了丰富的扩展端口,也可以看到,包括前、后面板、侧面、机身的顶部,都设计了大面积的通风、散热格栅,所以在散热方面完全不用担心,而且,即使在高负载的运行中,其噪音也没有很明显,即使是在安静的办公室环境,也不会打扰到其他人。

散热与功耗
对于一台高性能的迷你PC来说,散热和功耗控制同样重要。极摩客EVO-X2采用了北冰洋双风扇散热设计,内置三根散热铜管和三风扇,能够带来出色的散热效果。在峰值状态下,处理器的性能释放可以维持在140W左右,确保了机器在长时间高负载运行下的稳定性。


硬件配置:旗舰级配置,性能强劲
极摩客EVO-X2的核心竞争力在于其旗舰级的硬件配置。它搭载了AMD锐龙AI Max+ 395处理器,这款处理器基于卓越的Zen5架构,采用领先的4nm工艺,配备16颗超大核心32线程,最高加速频率可达5.1GHz,拥有80MB缓存(L2+L3),默认TDP为55W,可配置功耗区间为45~120W。这款处理器不仅单核和多核性能表现出色,还集成了基于RDNA 3.5架构的Radeon 8060S集显,配备40组CU计算单元,显卡频率为2900MHz,支持实时光追和AV1硬件编解码,图形性能远超传统集成显卡,甚至可以媲美中端独立显卡。

首先来看看锐龙AI Max+ 395处理器在极摩客EVO-X2 上的性能表现。
CINEBENCH R23
在CINEBENCH R23 的跑分中,AMD锐龙 AI Max+ 395 处理器的多核得分达到了36516 pts,单核得分1998 pts 的优秀成绩,处理器性能表现足够强悍。
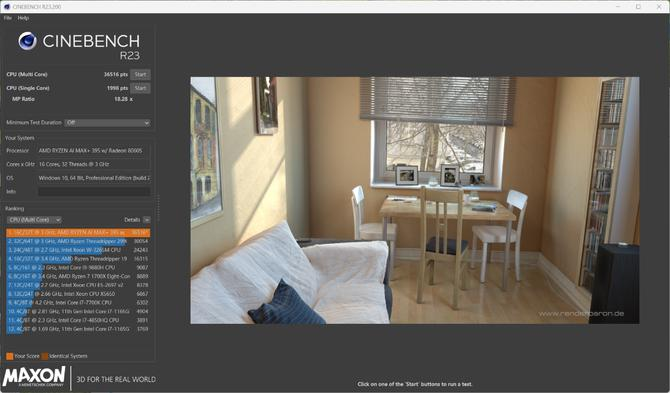
CINEBENCH 2024
CINEBENCH 2024增加了对内存的占用、计算的工作量等,以确保基准测试能匹配当代创意项目的复杂性。结果可见,锐龙 AI Max+ 395 处理器在CINEBENCH 2024的测试中,多核得分1807 pts,单核得分 113 pts,依然表现非凡。
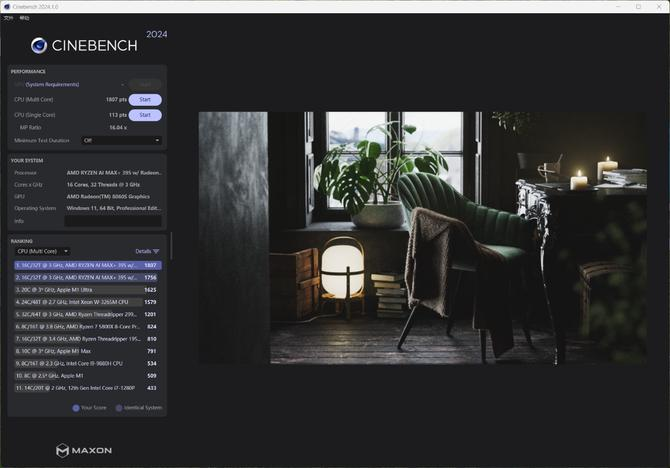
V-Ray Benchmark
V-Ray Benchmark渲染测试主要依赖多核心、多线程性能,尤其是AMD 的 SMT 技术,确保 CPU 能高效支撑渲染任务,避免因硬件适配问题导致的时间浪费或项目风险。测试的结果可见,获得 39259 个vsamples 。
7-Zip 基准测试
7-Zip内置的基准测试,可以用于评估CPU多线程性能,测试结果可见,压缩速度达到了148189 KB/s,解压缩速度2074309 KB/s,总体评分高达176.875 GIPS,这样的成绩显然很“恐怖”。

内存
为了能够匹配AMD锐龙AI Max+ 395这一旗舰处理器能够在性能、AI大模型方面的实力,本文评测的这台极摩客 EVO-X2还搭载了128GB统一内存,且可以将至高96GB的内存容量分配给Radeon 8060S iGPU作为集显显存,从而可以实现本地完整运行 Meta 的 Llama 4 Scout 109B 模型。

内存性能上,使用AIDA 64的内存测试结果可见,读取速度高达119.79 GB/s,写入速度211.52 GB/s,Copy速度154.23 GB/s,延迟 147.9 ns。
固态硬盘
硬盘存储方面,极摩客 EVO-X2搭配了Lexar PCIe 4.0 SSD,容量 2TB,而且,极摩客 EVO-X2还预留了多一个M.2 SSD硬盘位,容量方面基本上无忧。
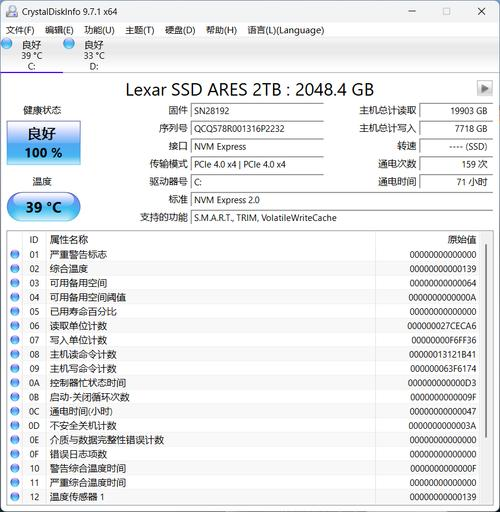
SSD的读写速度方面,实测的顺序读取速度为 7109.96 MB/s,写入速度为 5370.56 MB/s,速度飞快,尤其是4K随机读写的速度很高。
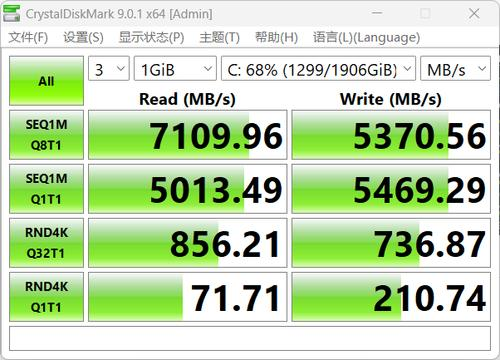
GPU
AMD的集成显卡从来没有让人失望过,在 3DMARK 图形计算任务中,Radeon 8060S 表现超越传统核显甚至追平中端独显,可轻松为图像 / 视频类 AI 模型提供稳定基础。
实际跑分结果,3DMark Time Spy 测试的显卡分数是11522,综合得分11196,优秀。

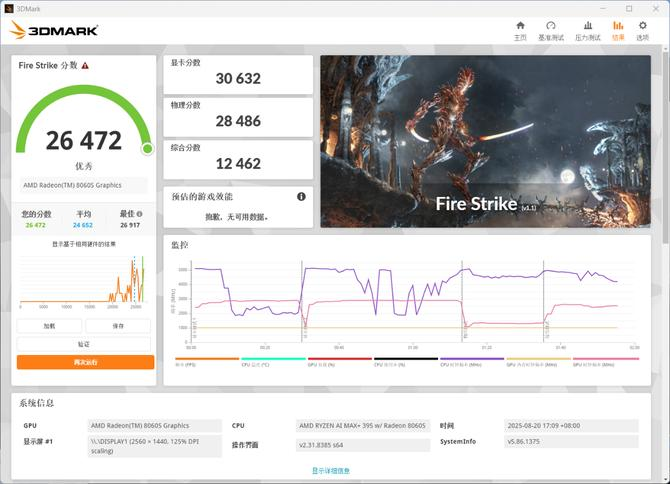
Fire Strike 测试中,显卡得分30632,综合得分 26472。
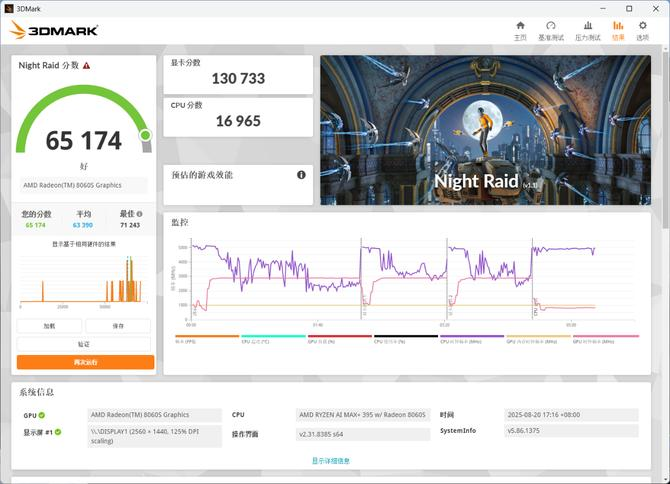
Night Raid 的测试中,显卡得分130733,综合得分65174。
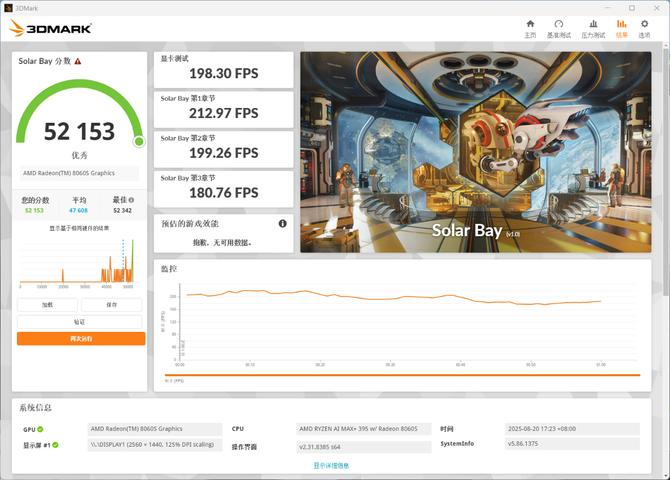
Solar Bay 光线追踪测试,显卡 198 FPS,三个章节均在180 FPS以上。
AI应用:本地部署大模型,轻松应对AI任务
极摩客EVO-X2的另一大亮点在于其强大的AI计算能力。得益于锐龙AI Max+ 395处理器内置的50 TOPS算力NPU,并支持高达128GB的超大统一内存,这款迷你PC能够轻松应对各种AI计算任务,甚至能够本地部署和运行大规模的语言模型。
过去,像 70B、32B 这种级别的语言模型,或者像 Flux 这样的图像生成模型,基本只能靠动辄几万块的云服务器来支撑运行。但 AMD锐龙 AI Max+ 395 算力强、内存大,支持统一内存技术,可以将 96GB 内存划归显存使用,还能灵活调度 CPU、GPU 和 NPU,让很多原本只能在云上跑的模型,如今在本地也能稳定高速地运行。而且对 AI 初学者或者入门级开发者来说,这也意味着门槛大幅降低 —— 以前不敢想的事,现在一台小主机就能完成,关键价格也能接受。
首先是AI Text Generation Benchmark(AI 文本生成基准测试),该测试用于评估 AI 模型在文本生成任务中综合性能的标准化测试工具或体系,核心目标是通过统一、可量化的指标,客观对比不同 AI 模型(或搭载 AI 模型的硬件设备)在文本生成场景下的表现,为开发者、用户选择合适的模型或硬件提供参考依据。
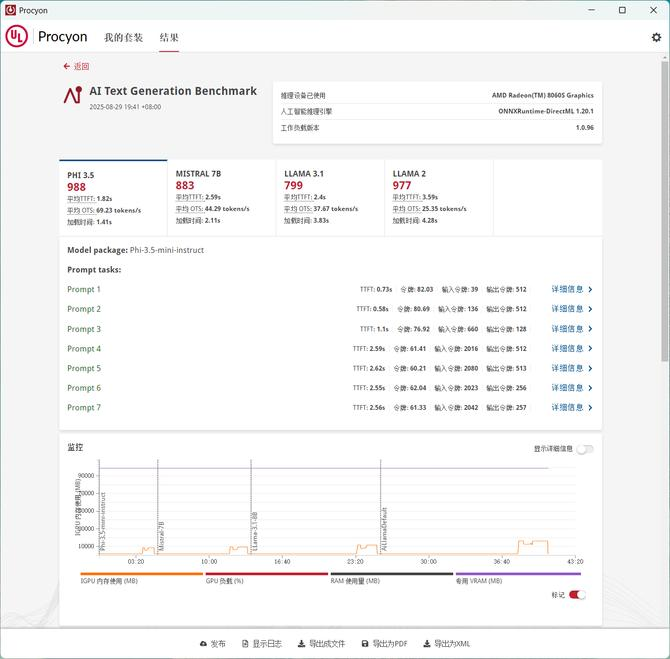
结果可见,四款大语言模型的平均速度都令人满意,这相比RTX 50系列初阶8GB显存的优势真的可以说是吊打。
对于总参数量高达 235B 的 Qwen3-235B-A22B-IQ2_S 大语言模型而言,其本地部署面临极高的性能开销挑战,主要体现在内存占用、算力需求及数据吞吐效率等核心维度。为实现该模型在终端设备的高效运行,本方案采用 AMD AI 生态合作伙伴模优优科技定制优化的模型文件,结合锐龙 AI Max+ 395 处理器的硬件架构优势与软件层优化策略,构建适配 AI PC 场景的运行体系。
具体技术路径如下:硬件层面依托锐龙 AI Max+ 395 的统一内存(Unified Memory Architecture)架构,将系统内存资源进行动态分配,最高可划设 96GB 容量作为显存(VRAM)使用,满足大模型权重加载与中间计算数据的存储需求;软件层面通过模优优科技的深度量化优化(IQ2_S 量化精度)与定制化内存调度算法,降低模型对硬件资源的单位需求。
实际运行阶段,通过 LM Studio 平台完成模型加载与对话任务初始化:启动 LM Studio 后,加载经优化的 Qwen3-235B-A22B-IQ2_S 模型文件,系统自动调用锐龙 AI Max+ 395 的异构算力资源与预配置的内存分配策略,待模型加载完成后即可启动交互式对话任务,实现全尺寸 235B 参数模型在 AI PC 端的流畅运行,突破传统终端设备无法承载超大规模模型本地部署的技术限制。
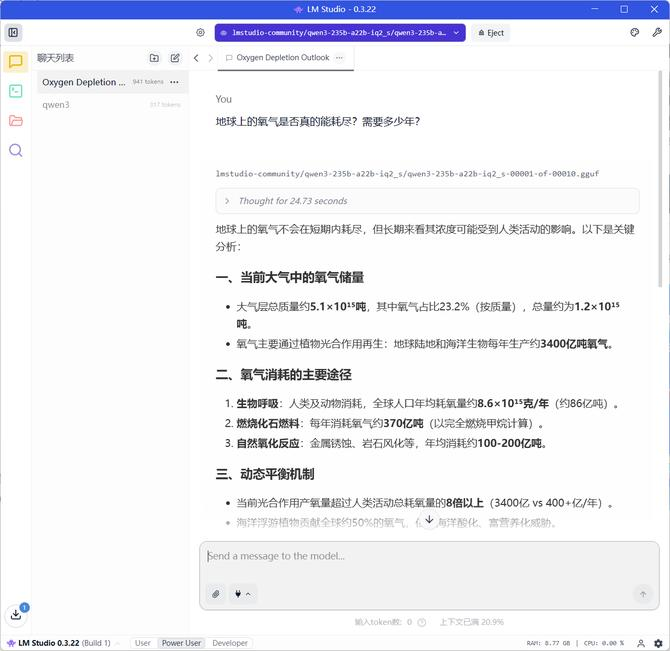
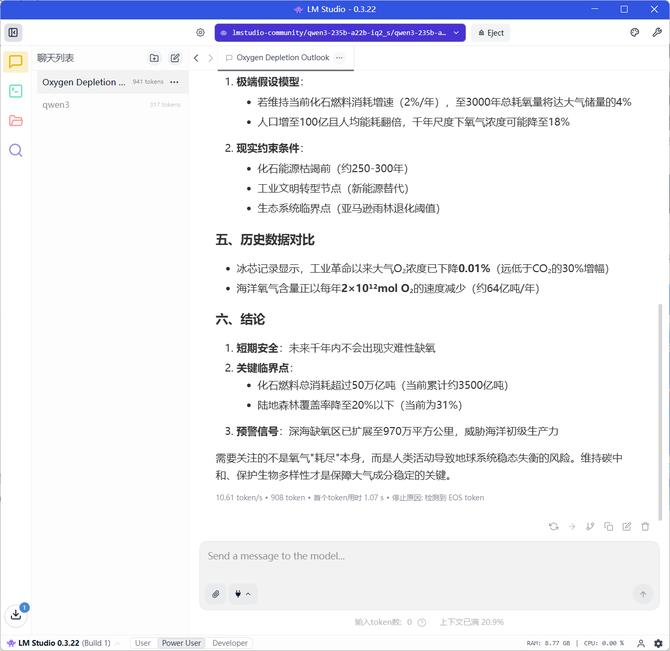
来验证一下。我们输入 “地球上的氧气是否真的能耗尽?需要多少年?”,这显然也没有固定的答案,所以 AI 给出的答案包括了当前大气中的氧气储量、主要的消耗途径、动态平衡的机制等,当然不会在可见的短期内耗尽了。来看看运算的结果:输出 908 token,用时 10.61 token/s ,首个 token 用时 1.07s。
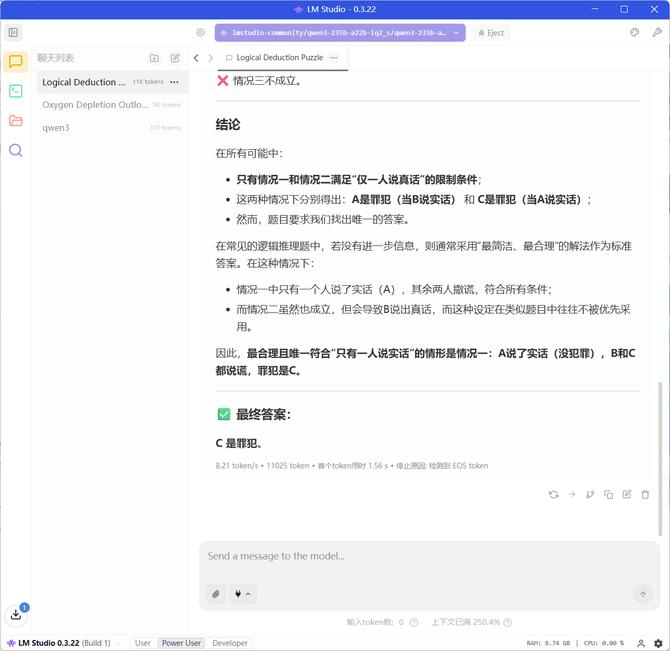
继续设定一个经典推理题:一个案件中,嫌疑人有A、B、C三个人。A说:“不是我干的”。B说:“是A干的”。C说:“是B干的” 。已知只有一个人说的是真话,那么罪犯是谁?
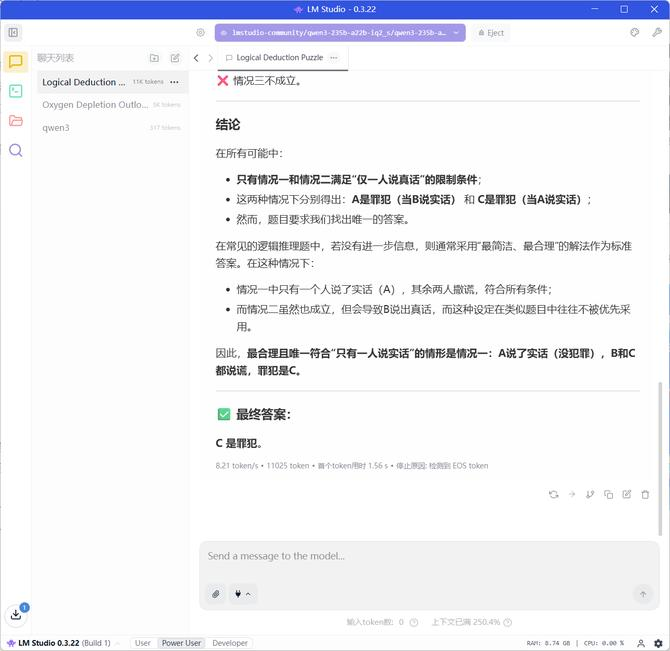
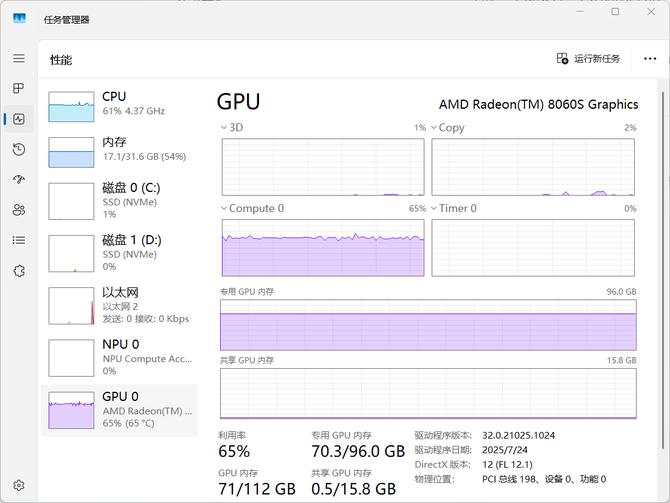
用时20分钟48秒,运算的结果:输出 11025 token,用时 8.21 token/s ,首个 token 用时 1.56s。
Amuse 是一款专为 Windows 系统 PC 打造的 AI 艺术创作应用程序,尤其针对 AMD 硬件进行深度优化,让用户能够借助最新的 Stable Diffusion 模型在本地设备生成图像。它的出现,极大地降低了创作者进入 AI 艺术创作领域的门槛,提供了便捷且高效的创作途径。
作为 AMD 的合作伙伴,Amuse 对 AMD 平台的 AI 性能进行了深度挖掘与优化。特别是在搭载锐龙 AI 处理器的设备上,其性能表现尤为突出。以极摩客EVO-X2所搭载的锐龙 AI Max+ 395 处理器为例,在使用 Amuse 进行文生图时,软件能够充分利用处理器的统一内存架构以及强大的计算单元。同时,Amuse 支持 AMD XDNA Super Resolution 功能,该功能允许利用 AMD 平台 NPU 的能力,对生成的图片进行超分处理,将分辨率提升至 2 倍。例如,生成一张初始分辨率为 1024×1024 的 “一只橘猫” 图片,在开启超分功能后,输出分辨率可达 2048×2048,且生成过程中,CPU、GPU、内存的资源调度分配合理。最终耗时仅 28.7s ,展现出高效的运算能力与图像生成效率。

与文生图类似,Amuse 的文生视频功能支持模型的本地部署。这意味着创作者无需依赖网络连接到云端服务器,避免了网络不稳定、数据传输限制以及隐私安全等问题。只要本地设备性能足够(如配备锐龙 AI 处理器及相应内存等硬件),就可以随时随地开展视频创作,大家不妨自行实践一下。
总结:
综上体验,极摩客 EVO-X2桌面Mini AI工作站以 “小体积、强性能、高 AI 算力” 为核心,既为 AI 开发者与学生提供了低成本的本地实验平台,也能满足内容创作者的专业需求与玩家的娱乐诉求,是当前迷你 PC 领域中 “AI 落地能力” 与 “综合性能” 平衡得极 佳的主机,当然,更是桌面 AI 超算中心的代表之作。






微信扫一扫:分享